
155mm im Spotlight
4. November 2025

18. August 2025 - von Eva Wolfangel
Wo stehen wir aktuell im Rennen um menschenähnliche künstliche Intelligenz – und wie sind wir dorthin gekommen? Wer die Geschichte der KI betrachtet, sieht, dass sich einige Muster immer wiederholen. Das hilft auch dabei, den aktuellen Hype einzuschätzen.
Künstliche Intelligenz
Werden selbstlernende Computerprogramme bald so gut denken können wie ihre Schöpfer? An dieser Frage scheiden sich die Geister. Klar ist: Künstliche Intelligenz verändert unsere Welt in einem beispiellosen Tempo. KI-Systeme analysieren komplexe Datenmengen, erkennen versteckte Muster und ziehen daraus Erkenntnisse – und das in einem Bruchteil der Zeit, die wir Menschen benötigen. Sie revolutionieren damit nicht nur die Forschung, die Produktion und den Krieg, sondern auch die Art, wie wir kommunizieren, planen und neue Dinge entwickeln. Deep Learning birgt jedoch auch Risiken: angefangen bei Fake-Videos und diskriminierenden Algorithmen bis hin zu Fragen der Kontrolle und Transparenz. Das Potenzial der Technologie zu nutzen, ohne ethische Grenzen zu überschreiten, bleibt die zentrale Herausforderung unserer Zeit.

Der Bauplan des Lebens
Neue Medikamente im Handumdrehen: KI-Modelle können mittlerweile nicht nur die Sprache der menschlichen DNA entschlüsseln, sondern auch die Form von Proteinen mit ihren komplexen Faltungen exakt und schnell voraussagen. Beides führt zu einem tieferen Verständnis biologischer Organismen, sodass sich irgendwann vielleicht Krankheiten wie Krebs heilen lassen. Die Herausforderungen in der Forschung: Die hochkomplexen und damit oft intransparenten KI-Modelle erschweren mitunter die Reproduzierbarkeit der Ergebnisse und den wissenschaftlichen Diskurs. Gleichzeitig benötigen sie enorme Rechenkapazitäten, die sich meist nur große Forschungseinrichtungen leisten können.

Produktivitätswunder
In der Industrie eröffnet maschinelles Lernen erhebliche Effizienzsteigerungen. KI-Systeme erkennen zuverlässig Fehlproduktionen, erstellen präzise Bedarfsprognosen und optimieren Lieferketten. Sie analysieren große Mengen an Produktions- und Sensordaten, um Fertigungsprozesse in Echtzeit zu steuern und teure Maschinenausfälle zu verhindern. Selbst komplexe Aufgaben können lernfähige Roboter zukünftig autonom erledigen. Noch sind viele Unternehmen mit der Implementierung von KI-Systemen überfordert: Die Investitionskosten sind hoch, die Anforderungen an Cybersicherheit und Datenschutz steigen, Fachkräfte fehlen.

Krieg der Algorithmen
Schon heute ermöglichen KI-basierte Systeme eine präzise Analyse von Aufklärungsdaten und identifizieren frühzeitig Bedrohungen. In Zukunft wird Künstliche Intelligenz noch sehr viel mehr eine Frage der Verteidigungsfähigkeit werden. Krieg ist komplex. Algorithmen unterstützen die Soldaten im Gefechtsfeld bei taktischen Entscheidungen, überwachen Flanken auf verdächtige Bewegungen und verbessern die Logistik. Autonome Systeme zu Luft, zu Wasser und an Land minimieren die Risiken für Soldaten. Wenn selbstlernende KI-Modelle irgendwann Gefechtsstrategien entwickeln, müssen sie zuverlässig gegen Cyberattacken geschützt und nachvollziehbar werden. Denn als letzte Instanz trifft nach wie vor der Mensch die Entscheidung.
Vor ziemlich genau zehn Jahren habe ich für eine Recherche einige der führenden deutschen Computerlinguisten getroffen. Damals war im Fach ein Streit ausgebrochen um die Frage: Können Maschinen unsere Sprache selbstständig, also allein auf der Basis von vielen Textbeispielen lernen? Ohne dass ihnen ein Mensch die Grammatik oder Wortbedeutungen erklärt und in festen Regeln hineinprogrammiert? Auf die Frage gab es seinerzeit keine eindeutige Antwort, nicht einmal eine klare Tendenz in Form einer wissenschaftlichen Mehrheitsmeinung. Doch dann passierte etwas Unerwartetes.
Hier muss ich etwas ausholen, um die Dimension verständlich zu machen. Denn die Vergangenheit führt direkt in die Gegenwart – und von hier aus in die Zukunft. Was sich damals ereignete, ist symptomatisch für die KI-Entwicklung: Es geschieht immer wieder, nur jeweils auf einer anderen Ebene. Wer das verstanden hat, kann sich selbst einen Reim machen auf die Zukunft.
Mit einem dieser Wissenschaftler, einem Computerlinguisten der Universität Stuttgart, hatte ich bereits länger Kontakt, weil mich dessen Arbeit faszinierte: Jonas Kuhn. Seine Gruppe hatte beispielsweise erforscht, dass und in welchem Ausmaß sich Menschen im Gespräch aneinander annähern – und zwar sowohl sprachlich als auch phonetisch. Damals wurde die Computerlinguistik nicht hauptsächlich als Disziplin der maschinellen Spracherzeugung betrachtet, wie es heute oft der Fall ist. Vielmehr hatte sie auch eine umgekehrte Wirkung: Denn mit den Mitteln der KI lässt sich auch viel über Menschen lernen. Das ist bis heute so, auch wenn das im Chatbot-Hype manchmal untergeht.
Die Stuttgarter Gruppe konnte 2012 schließlich nachweisen, dass Sympathie gewissermaßen messbar ist anhand dessen, wie sich Menschen sprachlich aneinander angleichen: Wenn ich eine Person sympathisch finde, passe ich mich während eines Gesprächs unbewusst sprachlich an.
Das Muster der KI: Von Durchbruch zu Durchbruch
Möglich geworden war diese Art von Forschung, weil die Technologie damals vorangeschritten war: Computer wurden immer leistungsfähiger und konnten immer größere Mengen an Daten verarbeiten. Künstliche Intelligenz trat in diesen Jahren ins Bewusstsein der Öffentlichkeit – zumindest der interessierten Öffentlichkeit: Denn das, was 2015 geschah, lässt sich durchaus als zweite KI-Revolution bezeichnen – dazu gleich mehr. Bis heute hat es in der Geschichte der KI drei dieser bedeutenden Fortschritte gegeben, die jeweils durch verbesserte Technologien ausgelöst wurden und jedes Mal grundlegende Diskussionen nach sich zogen. Und genau diese Entwicklung führte zum Streit im Fach der Computerlinguisten, also jener Forschungsrichtung, die den Grundstein gelegt hat für die heutige KI-Revolution, für die Geburt der großen Sprachmodelle. Ich erinnere mich noch gut an eine gewisse Empörung in der Stimme des Forschers, als er mir schließlich im Januar 2016 von kanadischen Wissenschaftlern aus der Bilderkennung berichtete. Diese hatten sich frecherweise in die Linguistik eingemischt – ganz ohne sich mit den Feinheiten der Sprachwissenschaft auszukennen. Doch genau das war der entscheidende Punkt gewesen: Die damalige Wissenschaft der Bilderkennung hatte nämlich als erste öffentlichkeitswirksam das sogenannte Deep Learning genutzt. Den Begriff kann man durchaus wörtlich nehmen: Mit der Zunahme der Rechenleistung war es möglich geworden, „tiefere“ neuronale Netze zu realisieren, Netze mit deutlich mehr Schichten als zuvor. Dadurch konnten noch größere Mengen an Daten noch feingranularer verarbeitet werden. Aber wie kann es sein, dass Systeme der Bilderkennung Sprache erzeugen?
Was genau ist KI eigentlich?
Bevor wir dazu kommen und zur Frage, um was die Linguistik damals stritt: Die Bilderkennung ist ein gutes Beispiel, um hier kurz innezuhalten und die Funktionsweise von KI zu erklären. Um Künstliche Intelligenz zu verstehen, ist vor allem ein Konzept wichtig: Mustererkennung. Bis heute ist das die Grundlage von KI. Auch die Erfolge von Chatbots liegen darin begründet.
Systeme maschinellen Lernens – und ich benutze das synonym zu KI, wozu wir aber gleich kommen – können besonders gut Muster in großen Datenmengen erkennen. Denken wir zum Beispiel an Katzenbilder: KI lernt, Bilder zu erkennen, indem sie mit zahlreichen Beispielen gefüttert wird – den sogenannten Trainingsdaten. Im Fall der Katzen bedeutet das: tausende Fotos mit Katzen und ebenso viele Bilder mit anderen Motiven.
Diese Bilder werden von Menschen annotiert, das heißt, sie fügen für die KI die Information hinzu, ob auf einem Bild eine Katze zu sehen ist oder nicht. Weil die Maschine Hinweise erhält, wird dieses Verfahren irreführenderweise als „überwachtes Lernen“ bezeichnet. Dennoch „lernt“ die KI von da an selbst, also eben gerade ohne Überwachung: Sie erkennt vielleicht, dass eine Katze vier Beine hat, zwei Ohren, Fell und so weiter. Das System extrahiert aus den Trainingsdaten jene Informationen, die es benötigt, um Katzenbilder von anderen Bildern zu unterscheiden. Es erkennt also gewissermaßen das „Muster“ von Katzen. Welche konkreten Faktoren die Maschine dabei für relevant befindet, bleibt für Menschen zunächst unklar. Deshalb gelten KI-Systeme oft als Blackbox. Ihre Entscheidungen lassen sich nicht nachvollziehen. Auch wenn es in der Transparenz inzwischen Fortschritte gibt, bleibt es im Prinzip dabei, dass solche Erklärungen stets nur Annäherungen sind.
Im Gegensatz zum überwachten Lernen steht das unüberwachte Lernen: Dabei erhält das KI-System Daten, in denen es selbstständig Muster erkennen soll – ganz ohne zusätzliche Vorgaben durch den Menschen. Die einzige Anweisung lautet beispielsweise: „Finde zehn Gruppen in diesen Daten.“ Das System sucht dann nach Mustern, die sich dafür eignen, die Daten in zehn sinnvolle Gruppen zu clustern. Oder „finde Auffälligkeiten in diesen Daten“. Solche Systeme lassen sich beispielsweise dazu nutzen, verdächtige Vorgänge in Netzwerken zu identifizieren. Das kommt heute beispielsweise in der IT-Sicherheit zur Anwendung, wenn KI-Systeme den Datenverkehr in einem Unternehmen beobachten, daraus die gewohnten Muster lernen und Alarm schlagen, wenn sich dieser Verkehr plötzlich auffällig verändert: Das könnten erste Anzeichen eines Cyberangriffs oder von Spionage sein.
Geschichte der KI: Die Definition ist mit der Technik mitgewachsen
Dieses „Lernen aus Daten“, das trotz der für Menschen oft nicht nachvollziehbaren Abläufe in KI-Systemen letztlich nichts anderes ist als eine statistische Auswertung großer Datenmengen, bildet das Herzstück heutiger künstlicher Intelligenz. Über die genaue Definition von KI lässt sich mit Fachleuten trefflich streiten, aber maschinelles Lernen als Basis dieser Definition zu verwenden, findet breite Zustimmung unter Experten.
Nichtsdestotrotz ist diese Definition im Laufe der Entwicklung mitgewachsen. Denn der Begriff künstliche Intelligenz wurde viel früher geprägt – zu einer Zeit, als viele ihn mit Computerprogrammen gleichsetzten, die damals noch die technologische Landschaft dominierten: regelbasierte, deterministische Anleitungen für Maschinen, die dann die vorgegebenen komplexen Berechnungen schlicht und einfach ausführten. Auch das kann zu Ergebnissen führen, die manchen Menschen durchaus „magisch“ erscheinen. Von daher hat sich der Begriff schon immer dazu geeignet, große Zukünfte zu imaginieren. Allerdings fielen diese Visionen auch immer wieder auf den harten Boden der Realität.


Der Begriff „Künstliche Intelligenz“ entstand vor beinahe siebzig Jahren. Im Sommer 1956 fanden sich zehn Wissenschaftler in New Hampshire, USA, zu einer Art Summerschool zusammen, dem „Dartmouth Summer Research Project on Artificial Intelligence“. Es gibt gute Gründe zu vermuten, dass der Begriff Künstliche Intelligenz damals vor allem aus Marketing-Gründen gewählt wurde: Die zehn Pioniere – darunter John McCarthy und Marvin Minsky – benötigten finanzielle Mittel für ihr Vorhaben. Und damals wie heute helfen fancy neue Begriffe mit Science Fiction-Anmutung erfolgreich beim Marketing.
So taucht der Begriff erstmals in einer Art Förderantrag auf, auch wenn die Summe im Vergleich zu den heutigen Investitionen in KI fast lächerlich gering erscheint: Die KI-Pioniere beantragten Reisekosten und Aufwendungen für den Lebensunterhalt in Höhe von insgesamt 13.500 US-Dollar für ihren achtwöchigen Workshop bei der Rockefeller Foundation. Man wolle ein „Seminar zur künstlichen Intelligenz“ durchführen, das von der Annahme ausgehe, „dass grundsätzlich alle Aspekte des Lernens und anderer Merkmale der Intelligenz so genau beschrieben werden können, dass eine Maschine zur Simulation dieser Vorgänge gebaut werden kann.“ Innerhalb von zwei Monaten wolle man herausfinden, „wie Maschinen dazu gebracht werden können, Sprache zu benutzen, Abstraktionen vorzunehmen und Konzepte zu entwickeln, Probleme von der Art, die zurzeit dem Menschen vorbehalten sind, zu lösen, und sich selbst weiter zu verbessern“. Man glaube, „dass in dem einen oder anderen dieser Problemfelder bedeutsame Fortschritte erzielt werden können, wenn eine sorgfältig zusammengestellte Gruppe von Wissenschaftlern einen Sommer lang gemeinsam daran arbeitet“. Was rückblickend klingt wie eine Prophezeiung, waren damals vor allem markige Worte. Im kurzen ersten Sommer der KI 1956 blieb der Durchbruch aus: Maschinen konnten zwar schließlich „Sprache benutzen“, doch auf recht ungelenke Art und Weise. Darüber konnte auch der Chatbot Eliza nicht hinwegtäuschen. Als eine der ersten Maschinen, die den Turing-Test bestanden, machte die Software ziemliche Schlagzeilen. Rückblickend klang es doch sehr nach jenem „stochastischen Papageien“, den heute noch viele Menschen hinter Sprachmodellen vermuten.
Das waren viele Begriffe – deshalb von vorn: Eliza ist ein Chatbot, der 1966 am Massachusetts Institute of Technology (MIT) entwickelt wurde. Er sollte eine Psychotherapeutin imitieren – was das Programm offenbar recht erfolgreich tat, denn tatsächlich konnten viele Menschen in der Interaktion am Bildschirm den Chatbot nicht definitiv von einem Menschen unterscheiden. Das ist das Kriterium wiederum für den Turing-Test, der prüft, ob sich eine Maschine im Dialog so verhält, dass ein Mensch sie für einen anderen Menschen hält. Wer sich heute mit Eliza unterhält, fragt sich allerdings, wie das passieren konnte: Die Antworten wirken nicht so, als ob Eliza wirklich „verstehe“, was ihr Gegenüber sagt.
Durchbruch Statistik: Die Geburt des modernen maschinellen Lernens – oder die erste KI-Revolution
Das liegt allerdings auch daran, dass KI in ihrer heutigen Form noch nicht existierte: Maschinelles Lernen, die Basis dessen, was heutige KI ausmacht, hatte seinen Durchbruch erst in den 1990er und 2000er Jahren. 1995 prägten die sogenannten Support Vector Machines das mathematische Fundament moderner KI-Algorithmen, und 1997 erschien das erste KI-Lehrbuch zur neuen Technologie des US-Informatikers Tom Mitchell mit dem schlichten Titel „Machine Learning“. Anfang der 2000er fanden diese ersten Ansätze ihren Weg in die Öffentlichkeit, als Amazon begann, mit seinem sogenannten Recommender System zu experimentieren: das bekannte Empfehlungssystem, das Kunden vorschlägt, welche Produkte sie auch interessieren könnten.
Die Modelle dieser Phase, der sogenannten statistischen Wende, konnten zwar schon erste Muster in Datensätzen finden – für Experten die erste KI-Revolution. Diese Suche funktionierte aber nur dann wirklich gut, wenn Menschen den Maschinen vorher genau sagten, worauf sie achten sollen. Mit Bildern, Sprache oder großen Datenmengen kamen sie kaum klar.
Deep Learning
ist ein Teilbereich des maschinellen Lernens, der auf künstlichen neuronalen Netzen (KNN) und großen Datenmengen basiert. KNN bestehen aus einer Vielzahl von Knoten, die miteinander verbunden und in mehreren „Schichten“ angeordnet sind. Diese digitalen Nervenzellen empfangen, verarbeiten, gewichten und übermitteln die Daten – von der Eingabeschicht über verdeckte Layer bis hin zur Ausgabeschicht, die das Endergebnis liefert. Mit Hunderten von verdeckten Schichten können KNN sehr komplexe Aufgaben erfüllen und präzise Vorhersagen treffen.
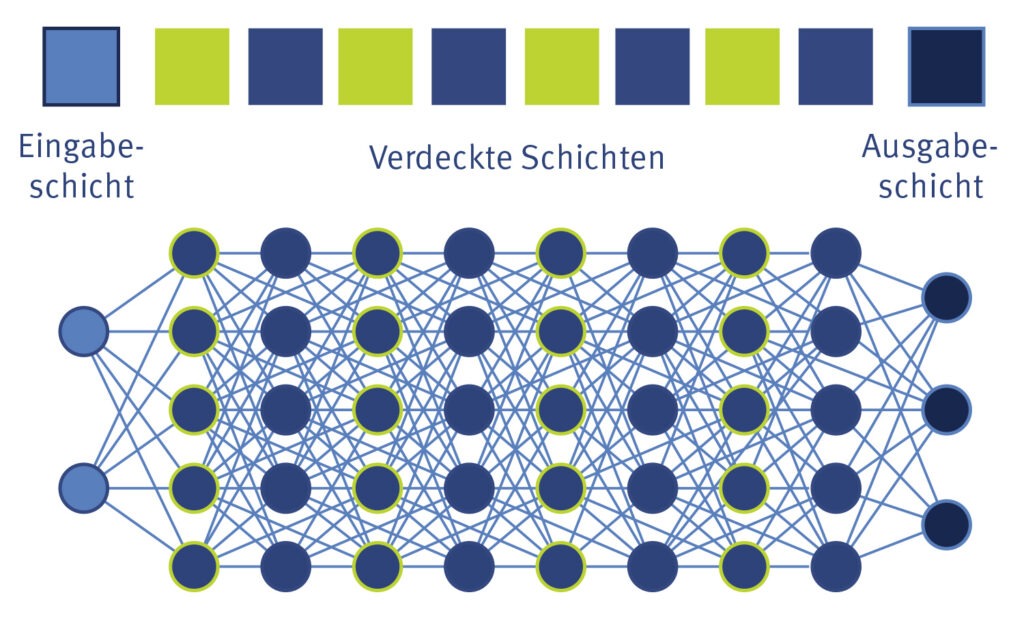
Entwickler trainieren KI-Systeme mit spezifischen Trainingsdaten, die das gewünschte Verhalten modellieren. Um die Genauigkeit der zu erwarteten Ergebnisse zu überprüfen, kommen Validierungsdaten zum Einsatz. Damit lässt sich auch beurteilen, wie das KNN die Trainingsdaten während der Lernphase verarbeitet. Nach dem Training wird die KI mit Hilfe der Testdaten bewertet.
Durchbruch Deep Learning
Das änderte sich 2015/16 zumindest ein Stück weit, und damit kommen wir zurück zur Linguistik und dem Streit im Fach: In jenen Jahren feierte das sogenannte Deep Learning seinen Durchbruch – wenn man so will, die zweite KI-Revolution. Sie zeigte sich zunächst in der Bilderkennung: Dank der nun leistungsfähigeren Technik konnten Maschinen Katzen (und allerlei anderes) viel besser erkennen als zuvor. Und es geschah noch etwas Seltsames: Jene Forscher aus der Visualisierung „warfen Texte in ihre Systeme“ – wie es Computerlinguisten mir gegenüber damals beschrieben – und erhielten recht passable Spracherzeugung.
Mit einem Schlag hatten die Visualisierungsexperten ein Ergebnis erzielt, für das die Computerlinguisten zuvor jahrelange Arbeit investieren mussten. Damit war klar: Der Einfluss der Menschen und ihrer grammatikalischen Regeln ist weit geringer als gedacht. KI kann offenbar in Massen von Sprach- und Text-Daten Muster erkennen, die dazu führen, dass sie Sprache erzeugen kann – ganz ohne deren Regeln zu kennen.
KI findet also Muster, die uns Menschen nicht bewusst sind. Letztlich führt diese Musterkennung zur Leistungsfähigkeit von KI, wie wir sie heute sehen. Aber es brauchte weitere Durchbrüche.


Durchbruch Attention
Denn dank generativer KI wie Chatbots und Bildgeneratoren kann die Öffentlichkeit heute live verfolgen, wie „gut“ KI inzwischen ist. Ausgelöst wurde diese dritte KI-Revolution ebenfalls durch einen technischen Fortschritt: den sogenannten „Attention“-Ansatz, der die Grundlage nahezu aller großen Chatbots bildet. Im berühmten Paper „Attention is all you need“ zeigten Forscher von Google Research schon 2017, dass ein verhältnismäßig einfacher Mechanismus zu einer besseren Leistung in maschineller Sprachverarbeitung führt als die sogenannten rekursiven Modelle, die bis dahin als das Nonplusultra galten.
All you need is Attention
Das Revolutionäre an fortschrittlichen KI-Modellen wie ChatGPT sind ihre Aufmerksamkeitsmechanismen. Statt alle Teile einer Dateneingabe gleichwertig zu betrachten, berechnen die Lernalgorithmen, welche der Informationen für die Ausführung der Aufgabe relevant sind und wie stark die betreffenden Daten zueinander in Beziehung stehen. Durch diese selektive Fokussierung können sie komplexe Zusammenhänge und Abhängigkeiten in Daten weitaus effektiver verstehen und interpretieren. Gleichzeitig bleibt der Zugriff auf den Gesamtkontext erhalten, sodass keine aussagekräftigen Details verloren gehen.
Was zunächst eine interessante Idee war, hat Sprachmodelle revolutioniert. Seither sind sie wahrlich eloquent – mit allen problematischen Folgen wie jener, dass Menschen ihnen allzu leichtfertig glauben, obwohl sie Unsinn behaupten.
Dass KI auf diese Weise so sprachgewandt werden würde, war zuvor nicht absehbar. Selbst Fachleute haben den Durchmarsch von ChatGPT & Co. fasziniert beobachtet. Und auch das zieht sich ebenso wie die Wellenbewegung des Auf und Abs durch die Geschichte der KI: ihre unerwarteten Erfolge. KI-Fortschritte scheinen schwer vorhersagbar zu sein. Das hängt auch damit zusammen, dass sich vieles, was in diesen Modellen geschieht, nicht erklären lässt – was zu Herausforderungen, auch in bestimmten Anwendungsfällen, führt.
Von Unerklärbarkeit bis Rassismus: Probleme der KI bis heute
Denn schließlich beschränkt sich unsere Interaktion mit KI nicht auf die weitgehend belanglosen Chats, die derzeit viele mit ihr führen. Im Alltag wirkt KI seit vielen Jahren für uns alle im Hintergrund – sei es in Form von Navigationssystemen, Sprachsteuerung wie Siri oder Amazon Alexa oder auch teils fragwürdigen Kreditentscheidungen, die unter anderem auf Verzerrungen in den Trainingsdaten beruhen könnten. So gab und gibt es immer wieder Beispiele von algorithmischen Systemen, die beispielsweise Frauen geringere Kredite zusprechen als Männern, selbst bei gleichem Einkommen. Oder Systeme in Bewerbungsverfahren, die im Hintergrund rassistische oder sexistische Kriterien berücksichtigen und bestimmte Bewerberinnen und Bewerber systematisch benachteiligen.
Oft werden diese sogenannten Biases – Verzerrungen – nicht wahrgenommen, weil sie für uns Menschen unsichtbar sind. Wie KI-Systeme ihre Entscheidungen treffen, können wir weder einsehen, noch wird es uns von ihnen erklärt. In den Trainingsdaten hingegen stecken Jahrtausende globaler Machtverhältnisse, schlicht der Rassismus, Sexismus, die Ausgrenzungen der Menschheit. Diese lassen sich nur schwer so weit „aufräumen“, dass sie nicht immer wieder zu Tage treten. Denn auch sie verbergen sich auf vielfache Weise in Mustern in diesen Daten, die uns Menschen nicht bewusst sind oder die wir nicht intuitiv aufspüren.

Vertrauenswürdige KI
Wer in der Entwicklung Künstlicher Intelligenz (KI) erfolgreich sein will, benötigt leistungsfähige Prozessoren und jede Menge Energie, Daten und Sachverstand. Aktuell dominieren China und die USA den Markt. Europa will im globalen Rennen aufholen. Wichtige Weichen dafür hat unter anderem der Artificial Intelligence (AI) Action Summit gestellt, der im Februar 2025 im Pariser Grand Palais stattgefunden hat: Ab 2026 sollen europaweit fünf KI-Gigafactorys entstehen. Nutzen kann die geplante Infrastruktur mit über 100.000 KI-Chips pro Standort grundsätzlich jeder. Mit einer solchen Demokratisierung der Rechenleistung will die Europäische Union der Forschung und der Wirtschaft ermöglichen, unabhängig von den großen Tech-Konzernen komplexe KI-Modelle zu entwickeln. Für deren Training sind hochqualitative Daten entscheidend. Und davon besitzt allen voran die europäische Industrie mehr als genug. Brüssel plant, dafür einen Binnenmarkt zu schaffen. Die notwendigen Rahmenbedingungen setzt der EU AI Act als weltweit erstes KI-Gesetz. Kann Künstliche Intelligenz sicher, inklusiv und vertrauenswürdig sein? Wer, wenn nicht Europa, hat das Potenzial, das zu beweisen.
Damit KI tatsächlich alltagstauglich wird, braucht es deshalb Regulierungen und Innovationen, die diese Schwächen eliminieren – auch wenn das alles andere als einfach ist. Die EU-Gesetzgebung, der sogenannte AI Act, ist hierfür ein erster Ansatz. Kritische Stimmen bemängeln, er sei zu streng, und warnen, dass er Innovationen in Europa endgültig ausbremsen könnte. Das Gesetz zeigt aber auch, was noch alles fehlt zu robuster und fairer KI: unter anderem Erklärbarkeit, Transparenz und der Nachweis, dass Verzerrungen ausgemerzt sind oder zumindest Entscheidungen nicht beeinflussen.
Die große Frage ist: Wie kommen wir zu sicheren, transparenten, sich selbst erklärenden KI-Systemen? Der bisherige Weg, bei dem Menschen erst dann erkennen, dass etwas schiefläuft, wenn diese Systeme falsche oder gar gefährliche Entscheidungen treffen, kann nicht das Ende der Fahnenstange sein.
Rettung oder Gefahr: Starke KI
Manche setzen auf eine andere Option: wirklich intelligente KI. Denn wenn KI tatsächlich so intelligent ist wie Menschen, könnte sie – so die Hoffnung – auch wirklich intelligente Entscheidungen treffen. Allerdings besteht hier auch das Risiko, dass sie einen eigenen bösen Willen entwickelt und damit richtig gefährlich wird. Darauf basieren all die Doomsday-Szenarien, von denen immer wieder zu hören ist. Ich persönlich bin der Ansicht, dass es wesentlich wahrscheinlicher ist, dass eine solche allgemeine KI hilfreich sein wird. Zumindest von sich aus. Was Kriminelle oder Diktatoren mit ihr machen, ist eine andere Frage. Denn dass eine KI einen eigenen bösen Willen entwickelt, erscheint mir wenig plausibel. Die aktuelle dritte KI-Revolution macht zwar richtig Wirbel. Aber noch steht der Beweis aus, dass sie KI tatsächlich auf eine neue Stufe heben kann, die näher an menschlicher Intelligenz ist. Die Rede ist von Allgemeiner Künstlicher Intelligenz – AGI (Artificial General Intelligence).


Was braucht es für die vierte KI-Revolution?
Wenn wir nun am Ende dieses Textes auf den Anfang schauen, wird klar, dass die Wette wieder aktuell ist. Wenn man sich die Entwicklung wie eine Spirale vorstellt, also quasi eine Kreisbewegung, die sich in den Raum ausdehnt und bei der sich die gleichen Themen stets wiederholen, allerdings jeweils auf einer neuen, fortgeschritteneren Ebene, dann sind wir mit der Frage „Reicht Statistik allein?“ in der obersten Etage angekommen. Es geht also nicht mehr nur darum, ob Statistik reicht, um Empfehlungen zu geben oder Sprache zu lernen, sondern ob sie auch „für alles“ reicht: Kann sich künstliche Intelligenz allein aus Sprachdaten nicht nur Sprache, sondern die ganze Welt erschließen?
Wieder gibt es zwei Lager: Während manche Fachleute schon schwärmen, dass Sprachmodelle der erste Schritt zu AGI sind und dass man sich offenbar die Welt auch komplett aus Sprachdaten zusammenreimen kann, warnen andere: Chatbots simulieren nur Verständnis. Ohne echtes Verständnis aber, so sagen sie, wird es keine grundlegenden Fortschritte in der KI geben. Während die einen argumentieren, dass KI immer besser wird, wenn größere Modelle und mehr Trainingsdaten zur Verfügung stehen, sagen die anderen: Wir haben ein Plateau erreicht, auf dem die klassische Skalierung („höher, schneller, weiter“) keine durchschlagenden Erfolge mehr bringen wird.
Gleichzeitig verdeutlichen Entwicklungen aus China (wie der Chatbot Deepseek), dass man möglicherweise auch mit weniger Aufwand und einer anderen Architektur weit kommen kann. Und das wiederum zeigt, dass allein Milliardeninvestitionen wie die von der US-Regierung nicht alles bedeuten, sondern es vielleicht auch noch einen „echten“ Durchbruch braucht: die vierte KI-Revolution.
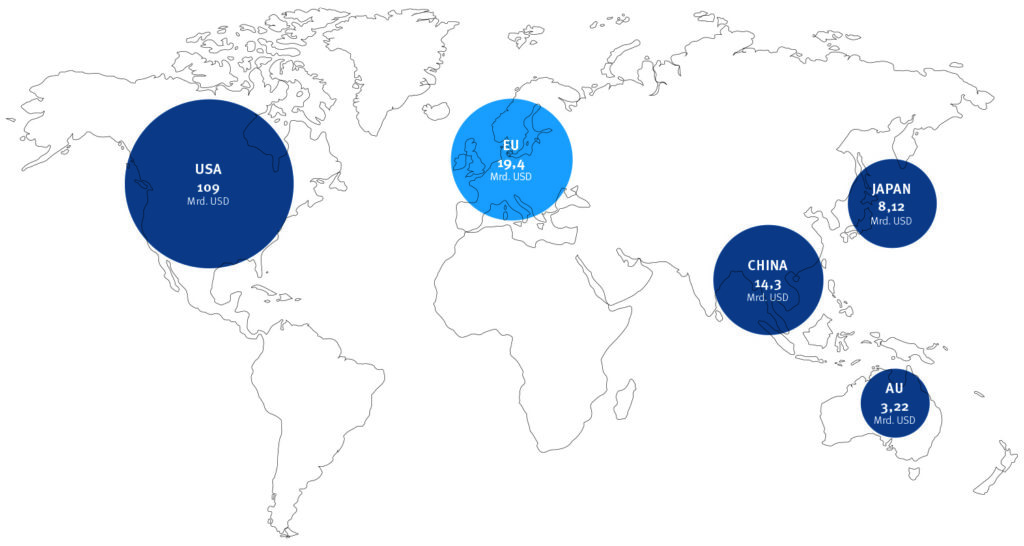
Wettrüsten um die KI-Vorherrschaft
Auch 2024 dominieren wieder die USA den globalen Markt für private Investitionen in Künstliche Intelligenz. Weit abgeschlagen folgt die Europäische Union (inklusive Großbritannien), danach China. Alle der genannten Nationen möchten für die nächsten Jahre zusätzliches Kapital und Staatsfonds in Milliardenhöhe mobilisieren: die USA 500 Mrd. USD, China rund 137 Mrd. USD und die EU 200 Mrd. USD.
Quellen: Statista Research Department u.a.
Erste Forscher sagen nun, dass sich der Mensch vielleicht doch wieder mehr einmischen muss. Sei es in Form von „Lehrbüchern für KI“ – also speziell von Menschen kuratierten Trainingsdaten – oder in Form von „symbolischer KI“: Systeme, die wieder mehr auf logischen Regeln basieren.
Wer glaubt, dass sich Geschichte wiederholt, wird sich von diesem Ansatz abwenden. Ich neige ebenfalls zur Plateau-Fraktion, kann mich aber nicht mit dem Gedanken anfreunden, dass es mehr menschlichen Input braucht. Diesen brauchte es schließlich auch nicht für die bisherigen Durchbrüche. Für mich ist aber eines auf jeden Fall klar: Allein Sprache reicht nicht aus als Basis für allgemeine KI. Was die Welt im Innersten zusammenhält, wird noch auf anderen Ebenen transportiert und verstanden. So beeindruckend Chatbots sind: Ein Teil ihres Erfolges beruht schlicht darauf, dass wir Menschen gut zu täuschen sind und Eloquenz mit Intelligenz verwechseln.

Eva Wolfangel
ist preisgekrönte Journalistin, Speakerin und Moderatorin. 2019/20 war sie als Knight Science Journalism Fellow am MIT in Boston, USA. 2020 wurde sie mit dem Reporterpreis, 2018 als European Science Journalist of the Year ausgezeichnet. Sie schreibt über Themen wie künstliche Intelligenz, virtuelle Realität und Cybersecurity.
Klicken Sie hier, um Push-Benachrichtigungen zu empfangen. Durch Ihre Einwilligung erhalten Sie regelmäßige Informationen zu neuen Beiträgen auf der Dimensions-Webseite. Dieser Benachrichtigungsservice kann jederzeit in den Browser-Einstellungen bzw. Einstellungen Ihres Mobilgeräts abbestellt werden. Ihre Einwilligung erstreckt sich ausdrücklich auch auf eine Datenübermittlung in Drittländer. Weitere Informationen finden Sie in unserer Datenschutzinformation unter Ziffer 5.


