
155mm in the spotlight
4. November 2025

18. August 2025 - from Eva Wolfangel
Where do we currently stand in the race concerning human-like artificial intelligence – and how did we get here? Looking back at the history of AI, certain patterns repeat themselves frequently. This also helps to assess the current hype.
Artificial Intelligence
Will self-learning computer programmes soon be able to think as well as their creators? Opinions are split on this question. One thing however is clear: artificial intelligence is changing our world at an unprecedented pace. AI systems analyse complex data sets, recognise hidden patterns, and draw conclusions – and they do so in a fraction of the time required by humans. They are revolutionising not only research, production, and warfare, but also the way we communicate, plan, and develop new things. However, deep learning also harbours risks, ranging from fake videos and discriminatory algorithms to questions of control and transparency. Harnessing the potential of this technology without crossing ethical boundaries remains the central challenge of our time.

The blueprint of life
New medication in no time: AI models can now not only decode the language of human DNA, but also accurately and quickly predict the shape of proteins with their complex folds. Both lead to a deeper understanding of biological organisms, which may eventually allow diseases such as cancer to be cured. The challenges in research: the highly complex and often opaque AI models sometimes make it difficult to reproduce results and engage in scientific discourse. At the same time, they require enormous computing power that only large research institutions can usually afford.

Productivity boost
Machine learning is opening up significant efficiency gains in industry. AI systems reliably detect production faults, generate accurate demand forecasts and optimise supply chains. They analyse large volumes of production and sensor data to control manufacturing processes in real time and prevent costly downtime of machines. Adaptive robots will even be able to perform complex tasks autonomously in the future. Many companies are still overloaded by the implementation of AI systems: investment costs are high, cyber security and data protection requirements are increasing, and there is a shortage of skilled workers.

The algorithm war
AI-based systems already enable precise analysis of reconnaissance data and identify threats at an early stage. In the future, artificial intelligence will become even more important for defence capabilities. War is complex. Algorithms support soldiers on the battlefield in making tactical decisions, monitor flanks for suspicious movements, and improve logistics. Autonomous systems in the air, at sea, and onland minimise risks for soldiers. If self-learning AI models eventually develop combat strategies, they must be reliably protected against cyberattacks and become traceable. After all, it is still humans who make the final decision.
Almost exactly ten years ago, I met some of Germany’s leading computer linguists for a research project. At the time, there was a heated debate in the field about whether machines could learn our language autonomously, i.e. solely based on numerous text examples, without a human being explaining grammar or connotations of words and programming this into them by means of fixed rules. At the time, there was no clear answer to this question, not even a precise trend in the form of a scientific majority opinion. But then something unexpected happened.
I need to take a step back here to explain the scale of this. The past leads directly to the present – and from here to the future. What happened back then is symptomatic of AI development: it happens again and again, just on a different level each time. Once you understand that, you can make sense of the future yourself.
I had already been in contact for some time with one of these scientists, a computer linguist at the University of Stuttgart, because I was fascinated by his work: Jonas Kuhn. His group had, for instance, researched how and to what extent people connect with each other in conversation – both linguistically and phonetically. At that time, computer linguistics in general was not primarily regarded as a discipline of machine language generation, as is often the case today. Rather, it also had the opposite effect: AI can also be used to learn a lot about people. This is still the case today, even if it sometimes gets lost in the chatbot hype.
In 2012, the Stuttgart group finally proved that sympathy is, to a certain extent, measurable, based on how people adapt their language to each other: if I find someone likeable, I unconsciously
adapt my language during a conversation.
The pattern of AI: From breakthrough to breakthrough
The advancement of technology at the time made this type of research possible: computers were becoming increasingly powerful and capable of processing ever larger amounts of data. Artificial intelligence entered public consciousness during these years – at least among those who were interested in the subject. What happened in 2015 can certainly be described as the second AI revolution – but more on that later. To date, there have been three such significant advances in the history of AI, each triggered by improved technologies and each followed by fundamental discussions. And it was precisely this development that led to controversy among computer linguists, the field of research that laid the foundation for today’s AI revolution and the birth of large language models. I can still remember the indignation in the researcher’s voice when he eventually told me about Canadian scientists working on image recognition in January 2016. They had brazenly meddled in linguistics without knowing anything about the intricacies of linguistics. But that was precisely the point: at the time, image recognition science was the first field to make effective use of so-called deep learning. The term can be taken quite literally: with the increase in computing power, it had become possible to create “deeper” neural networks, networks with significantly more layers than before. This allowed even larger amounts of data to be processed in even greater detail. But how can image recognition systems generate language?
What exactly is AI?
Before we get to this and to the question of what linguists were arguing about back then: image recognition is a good example to pause briefly and explain how AI works. To understand artificial intelligence, one concept is particularly important: pattern recognition. This remains the basis of AI to this day. The success of chatbots is also rooted in this concept.
Machine learning systems – and I use this term synonymously with AI, which we will come to in a moment – are particularly good at recognising patterns in large amounts of data. For example, take cat pictures: AI learns to recognise images by being fed numerous examples – known as training data. In the case of cats, this means thousands of photos of cats and just as many images with other subjects.
These images are annotated by humans: that is, information is added for the AI about whether or not a cat is shown in an image. Because the machine receives hints, this process is misleadingly referred to as ”supervised learning”. Nevertheless, from that point on, AI ”educates” itself, notably without supervision: it may recognise that a cat has four legs, two ears, fur, and so on. The system extracts the information it needs from the training data to distinguish cat images from other images. In a sense, it understands the ”pattern” of cats. Which specific factors the machine considers relevant remains unclear to humans at first. This is why AI systems are often regarded as black boxes. Their decisions cannot be traced. Even though progress has been made in terms of transparency, such explanations are always only approximations.
In contrast to supervised learning is unsupervised learning. Here, the AI system receives data in which it is supposed to recognise patterns independently – without any additional input from humans. The only instruction is, for example, “find ten groups in this data”. The system then searches for patterns that are suitable for clustering the data into ten meaningful groups. Or the instruction is “find anomalies in this data”. Such systems can be used, for example, to identify suspicious activity in networks. This is currently used in IT security, where AI systems monitor data traffic in a company, learn the usual patterns, and sound the alarm if this traffic suddenly changes in a noticeable way: this could be the first sign of a cyberattack or espionage.
History of AI: The definition has grown alongside the technology
Despite the processes in AI systems often being incomprehensible to humans, this ”learning from data” is ultimately nothing more than a statistical evaluation of large amounts of data, and forms the core of today’s artificial intelligence. The exact definition of AI is a matter of debate among experts, but using machine learning as the basis for this definition is widely accepted.
Nevertheless, this definition has evolved over time. The term ”artificial intelligence” was coined much earlier, at a time when many people equated it with computer programmes, which dominated the technological landscape at the time: rule-based, deterministic instructions for machines that simply carried out the specified complex calculations. This can also lead to results that some people find ”miraculous”. That’s why the term has always been good for imagining a greater future. But these visions have always come crashing down to earth.


The term ”artificial intelligence” was formulated almost 70 years ago. In the summer of 1956, ten scientists gathered in New Hampshire, USA, for a kind of summer school called the Dartmouth Summer Research Project on Artificial Intelligence. There are good reasons to believe that the term artificial intelligence was chosen primarily for marketing reasons at the time: the ten pioneers – including John McCarthy and Marvin Minsky – needed financial resources for their project. And back then, as today, fancy new terms referring to science fiction were a successful marketing tool.
The term first appeared in a kind of funding application, even if the amount seems almost laughably small in comparison to today’s investments in AI: the AI pioneers applied for travel expenses and living costs totalling USD 13,500 for their eight-week workshop at the Rockefeller Foundation. The aim was to hold a seminar on ”artificial intelligence ” based on the assumption “that all aspects of learning and other characteristics of intelligence can be described so precisely that a machine can be built to simulate these processes”. Within two months, they wanted to find out “how machines can be induced to use language, make abstractions, develop concepts, solve problems of the kind currently reserved for humans, and improve themselves”. They believed “that significant progress can be made in one or more of these problem areas if a carefully assembled group of scientists works together on them for a summer”. What sounds like a prophecy in retrospect was, at the time, mostly just bold words. In the short first summer of AI in 1956, there was no breakthrough: machines were finally able to ”use language”, but in a rather stiff way. Even the chatbot Eliza couldn’t hide that. As one of the first machines to pass the Turing test, the software made quite a few headlines. Looking back, it sounded very much like the “stochastic parrot” that many people still suspect language models to be today.
Those were a lot of terms – so let’s start from the beginning: Eliza is a chatbot, developed in 1966 at the Massachusetts Institute of Technology (MIT). It was designed to imitate a psychotherapist – which the programme apparently did quite successfully, because many people interacting with it on a screen were unable to definitively distinguish the chatbot from a human being. This is also the criterion for the Turing test, which checks whether a machine behaves in a dialogue in such a way that a human being mistakes it for another human being. However, anyone who talks to Eliza today wonders how this could have happened: the answers do not seem as if Eliza really “understands” what her counterpart is saying.
Breakthrough in statistics: The birth of modern machine learning – or the first AI revolution
However, this was partly because AI in its current form did not yet exist: machine learning, the basis of what constitutes AI today, only made its breakthrough in the 1990s and 2000s. In 1995, support vector machines formed the mathematical foundation of modern AI algorithms. A year later, the first AI textbook on the new technology was published by US computer scientist Tom Mitchell, simply titled Machine Learning. In the early 2000s, these initial approaches found their way into the public eye when Amazon began experimenting with its so-called Recommender System: the well-known recommendation system that suggests which products customers might also be interested in.
The models of this phase, known as the “statistical turning point”, were able to identify initial patterns in data sets, which experts considered to be the first AI revolution. However, this search only worked well if humans told the machines exactly what to look for beforehand. Such models struggled to cope with images, language, or large amounts of data.
Deep learning
is a subfield of machine learning based on artificial neural networks (ANNs) and large amounts of data. ANNs consist of a large number of nodes that are interconnected and arranged in several “layers”. These digital nerve cells receive, process, weigh, and transmit data – from the input layer through hidden layers to the output layer, which delivers the final result. With hundreds of hidden layers, ANNs can perform highly complex tasks and make accurate predictions.
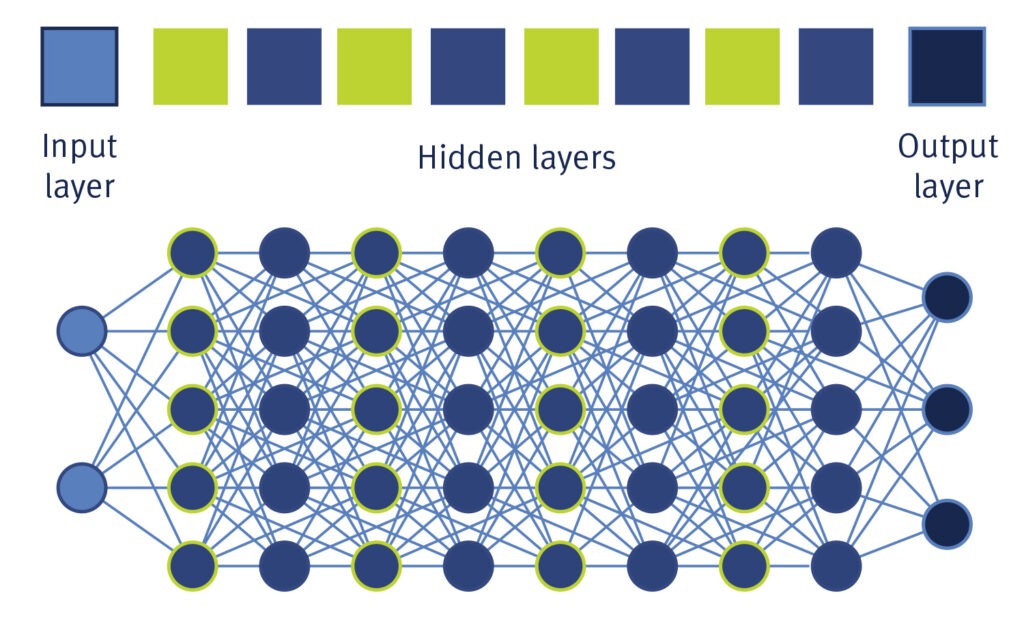
Developers train AI systems with specific training data that models the desired behaviour. Validation data is used to check the accuracy of the expected results. This also allows an assessment of how the ANN processes the training data during the learning phase. After training, the AI is evaluated using the test data.
Breakthrough in deep learning
That changed somewhat in 2015/16, which takes us back to linguistics and the debate within the field: those years saw the breakthrough of “deep learning” – the second AI revolution, so to speak. It first manifested in image recognition: thanks to more powerful technology, machines were able to recognise cats (and all sorts of other things) much better than before. And another strange thing happened: those researchers from the field of visualisation “threw texts into their systems”, as computer linguists described it to me at the time – and obtained quite passable language generation.
All of a sudden, the visualisation experts achieved a result that had previously taken computer linguists years of work. It was now clear that the influence of humans and their grammatical rules is far less significant than previously thought. AI is apparently capable of recognising patterns in large amounts of language and text data that enable it to generate language without knowing any rules.
AI therefore finds patterns that we humans are not aware of. Ultimately, this pattern recognition leads to the performance of AI as we know it today. But further breakthroughs were needed.


Breakthrough in attention
Thanks to generative AI, such as chatbots and image generators, the public can now follow live how “good” AI has become. This third AI revolution was also triggered by a technical advance: the so-called attention approach, which is the basis of almost all major chatbots. In their famous paper “Attention is all you need”, researchers at Google Research showed back in 2017 that a relatively simple mechanism leads to a better performance in machine language processing than the so-called recursive models, which had previously been considered as the ultimate solution.
All you need is attention
The revolutionary aspect of advanced AI models such as ChatGPT is their attention mechanisms. Instead of treating all parts of a data input as equal, the learning algorithms calculate which pieces of information are relevant for performing the task and how closely the relevant data are related to each other. This selective focus enables them to understand and interpret complex relationships and dependencies in data much more effectively. At the same time, access to the overall context is retained, so that no meaningful details are lost.
What started out as an interesting idea has revolutionised language models. Since then, they have become truly eloquent – with all the problematic consequences, such as people believing them too easily, even when they generate nonsense.
It was not foreseeable that AI would become so articulate in this way. Even experts have watched the rise of ChatGPT and Co. with fascination. And this, like the waves of ups and downs throughout the history of AI, is also a recurring theme: its unexpected successes. Advances in AI seem difficult to predict. This is also linked to the fact that much of what happens in these models cannot be explained – which leads to challenges, especially in certain cases of applications.
From inexplicability to racism: Problems with AI until today
After all, our interaction with AI is not limited to the largely trivial chats that many of us currently engage in with it. AI has been working for us all in the background for many years – whether in the form of navigation systems, voice control such as Siri or Amazon Alexa, or even questionable creditworthiness decisions that also could be based on distortions in the training data. There have been and continue to be examples of algorithmic systems that grant women lower loans than men, even when they have the same income. Or there are systems in application processes that take racist or sexist criteria into account in the background and systematically disadvantage certain applicants.
These so-called biases often go unnoticed because they are invisible to us humans. We cannot understand how AI systems make their decisions, nor do they explain it to us. The training data, on the other hand, contains thousands of years of global power relations – in other words racism, sexism, the exclusion of humanity. It is difficult to “clean up” these biases to such an extent that they do not keep resurfacing. This is because they are also hidden in many ways in patterns in this data that we humans are not aware of or cannot intuitively detect.

Trustworthy AI
Anyone who wants to be successful in the development of artificial intelligence (AI) needs powerful processors and lots of energy, data, and expertise. China and the USA are currently dominating the market. Europe wants to catch up in the global race. Important steps in this direction were taken at the Artificial Intelligence (AI) Action Summit held at the Grand Palais in Paris in February 2025: starting in 2026, five AI gigafactories are to be built across Europe. With over 100,000 AI chips per location, the planned infrastructure can be used by anyone. With this democratisation of computing power, the European Union wants to enable research and industry to develop complex AI models independently of the big tech companies. High-quality data is crucial for training these models, and European industry has more than enough of it. Brussels plans to create a single market for this purpose. The EU AI Act, the world’s first AI law, sets the necessary framework. Can artificial intelligence be safe, inclusive, and trustworthy? Who else but Europe has the potential to prove it?
For AI to become truly suitable for everyday use, regulations and innovations are needed to eliminate these weaknesses, even if this is anything but easy. EU legislation, known as the AI Act, is a first step in this direction. Critics argue that it is too strict and warn that it could ultimately stifle innovation in Europe. However, the law also highlights what is still lacking in terms of robust and fair AI, including explainability, transparency, and proof that biases have been eliminated or at least do not influence decisions.
The big question is: how do we achieve secure, transparent, self-explanatory AI systems? The current approach, whereby humans only realise that something is wrong when these systems make incorrect or even dangerous decisions, cannot be the right way to go.
Salvation or danger: Powerful AI
Some are betting on a different option: truly intelligent AI. After all, if AI is really as intelligent as humans, it could – so the hope – also make truly intelligent decisions. However, there is also a risk that it will develop its own evil attitude and thus become truly dangerous. This is the basis for all the doomsday scenarios we keep hearing about. Personally, I believe that it is much more likely that such general AI will be helpful. At least when operating on its own initiative. What criminals or dictators will do with it is another question. However, it seems implausible to me that AI will develop its own evil attitude. The current third AI revolution is certainly causing quite a stir. But it remains to be seen whether it can actually take AI to a new level which is closer to human intelligence. We are talking about artificial general intelligence (AGI).


What is needed for the fourth AI revolution?
If we now look back to the beginning of this text, it becomes clear that the bet is back on. If you imagine development as a spiral, a circular movement that expands into space and in which the same themes keep repeating themselves, albeit at a new, more advanced level, then we have arrived at the top floor with the question “Are statistics alone enough?” Thus, it is no longer just a question of whether statistics are sufficient for making recommendations or learning languages, but whether they are sufficient “for everything”: Can artificial intelligence use language data alone to understand not only language, but the whole world?
Once again, there are two camps: while some experts are already raving that language models are the first step towards AGI and that it is apparently possible to piece together the entire world from language data, others are warning that chatbots only simulate understanding. Without genuine understanding, they say, there will be no fundamental progress in AI. While some argue that AI will continue to improve as larger models and more training data become available, others say that we have reached a plateau where the classic scaling (“higher, faster, farther”) will no longer yield significant gains.
At the same time, developments in China (such as the chatbot DeepSeek) show that it may be possible to achieve a lot with less effort and a different architecture. This in turn shows that billion-dollar investments like those made by the US government are not everything, but that a “substantial” breakthrough may still be needed: the fourth AI revolution.
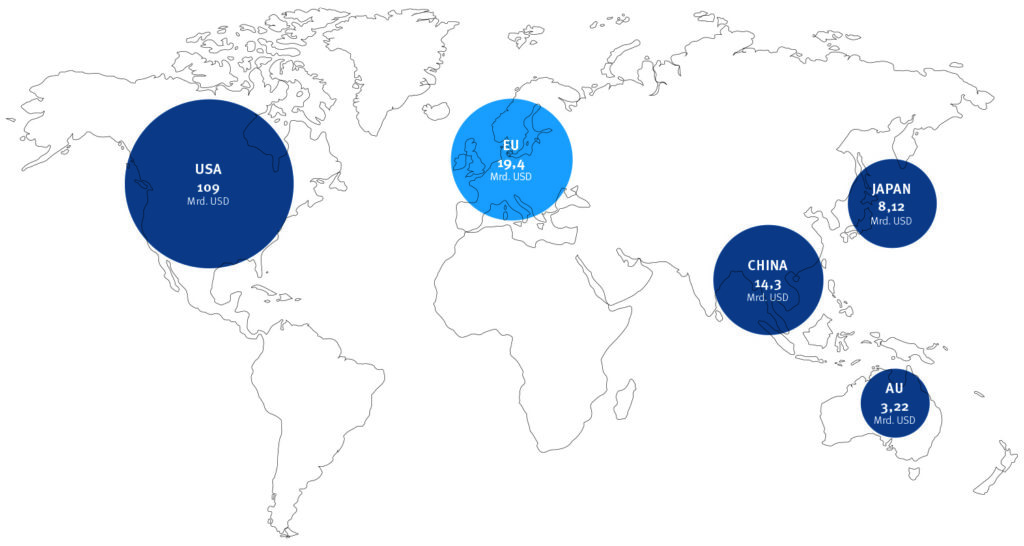
AI supremacy
In 2024, the USA once again dominated the global market for private investment in artificial intelligence. The European Union (including the United Kingdom) followed far behind, with China in third place. Each of them wants to mobilise additional capital and sovereign wealth funds amounting to
billions over the next few years: the USA with USD 500 billion, China around USD 137 billion and the
EU USD 200 billion.
Sources: Statista Research Department and others.
Some researchers are now saying that humans may need to intervene more after all. This could take the form of “AI textbooks” – training data specially curated by humans – or “symbolic AI”: systems that are once again based more on logical rules.
Anyone who believes that history repeats itself will reject this approach. I also lean towards the plateau faction, but I cannot warm to the idea that more human input is needed. After all, it was not necessary for the breakthroughs achieved so far. For me, however, one thing is clear: language alone is not sufficient as a basis for AGI. What holds the world together at its core is conveyed and understood on other levels. As impressive as chatbots are, part of their success is simply due to the fact that we humans are
easily deceived and confuse eloquence with intelligence.

Eva Wolfangel
is an award-winning journalist, speaker, and presenter. In 2019/20, she was a Knight Science Journalism Fellow at MIT in Boston, USA. She was awarded the Reporter Prize in 2020 and named European Science Journalist of the Year in 2018. She writes about topics such as artificial intelligence, virtual reality, and cybersecurity.
Click here to receive push notifications. By giving your consent, you will receive constantly information about new articles on the Dimensions website. This notification service can be canceled at any time in the browser settings or settings of your mobile device. Your consent also expressly extends to the transfer of data to third countries. Further information can be found in our data protection information under section 5.


